Recently, the Chrome developers announced their decision to remove the behind-a-flag support for JPEG XL. The following reasons are cited for this decision:
- Experimental flags and code should not remain indefinitely
- There is not enough interest from the entire ecosystem to continue experimenting with JPEG XL
- The new image format does not bring sufficient incremental benefits over existing formats to warrant enabling it by default
- By removing the flag and the code in M110, it reduces the maintenance burden and allows us to focus on improving existing formats in Chrome
The first statement makes sense, but many people expected that it would be resolved by enabling the feature by default, not by removing the feature entirely. This does not justify this decision at all.
However, understanding the broader context of how users interact with image formats in browsers is essential. Everyday practices like saving and converting images within web browsers, which are commonplace for the average user, aren’t directly addressed in the case of JPEG XL.
As for the second point: the question is if and how the interest of the ecosystem was gauged. Since the feature has been locked behind a flag, obviously any actual deployment has been blocked — disabled-by-default features can be used for experimentation, but not for actual deployment since the bulk of the end users will not have the flag enabled. So there are no meaningful usage statistics to look at.
The main part of the JPEG XL standard (ISO/IEC 18181-1) was published in March 2022, about half a year ago. The part describing the reference implementation (ISO/IEC 18181-4) was published in August 2022, about three months ago. It seems to be rather premature to draw any conclusions about “ecosystem interest” at this early stage.
However, if the enthusiastic support in the Chromium bugtracker from Facebook, Adobe, Intel and VESA, Krita, The Guardian, libvips, Cloudinary, and Shopify is any indication, it seems baffling to conclude that there would be insufficient ecosystem interest.
That brings us to the third and perhaps most important point: “Not sufficient incremental benefits over existing formats.”
Of course “not sufficient” is a rather vague criterion, if it is not specified what the threshold is for a benefit to be considered sufficient. In this blog post we will take a closer look at what the benefits are, and then you can judge for yourself whether they are “sufficient” or not.
Regarding the fourth point: yes, obviously every extra line of code introduces a “maintenance burden”, but that’s a rather generic argument that applies to any new feature. But in this particular case, the burden is arguably relatively modest.
The actual implementation of JPEG XL in Chrome is based on an integration of libjxl, which is itself not maintained by Chrome, though they do have to assess and possibly even mitigate — if the libjxl developers would not provide a timely response — potential security bugs that could get discovered in it, like with any ‘third party’ library integrated in Chrome. All the integration work has already been done, including what is needed to make alpha transparency, animation, color management including HDR, and progressive decoding work properly. The main remaining “burden” we are still talking about at this point essentially amounts to occasionally bumping up a version number in a build script, in case there is a new version of libjxl that brings improvements that are useful for Chrome. The Chrome team has not been working on improving libjxl in the past (and is also not expected to do that, to be clear), so it is not clear how removing the flag would make a difference in their ability to focus on other things.
A unique feature of JPEG XL is that it is possible to recompress existing JPEG images (of which there are a lot out there!) to a JPEG XL file that is on average about 20% smaller, without introducing any loss. In fact, the bit-exact same JPEG file can be reconstructed from the JPEG XL file.
No other image format has this feature, which means that they don’t have a satisfactory solution to make the transition from JPEG: existing JPEG files can either be kept as JPEG — using the new format only for new images — or they can be transcoded to the new format. However, transcoding is a somewhat problematic operation. In any case, it is a lossy operation, adding more compression artifacts on top of the already-lossy JPEG. But it can also be counterproductive: if you select a high transcoding quality, the additional loss can be minimized but you might end up with a file that is larger than the JPEG you started with (similar to what happens if you convert a JPEG image to PNG). If you select a low enough transcoding quality, you will be able to reduce the file size, but it comes at the cost of additional compression artifacts. It is hard to automate such a transition process in a way that avoids these issues.
The old JPEG format supports progressive decoding: when just 15% of the image data has been transferred, a lower-quality preview of the image can already be shown, which then gets refined as more data arrives. This is a feature originating from the dial-up days of the internet, but it is still very useful today in a world where average network speeds and image resolutions both increased significantly, but the variation in network conditions has increased too. On a fast cable or 5G connection, progressive decoding merely makes page loading feel a little ‘snappier’, but on a flimsy 3G connection on the road, it makes the difference between seeing something and seeing nothing at all.
Thanks in part to MozJPEG gaining traction as a JPEG encoder, progressive JPEG has been the fastest-growing web image format in the past decade, if you treat it as a separate format from the baseline sequential JPEG mode.
None of the video-derived image formats (WebP, HEIC, AVIF) support progressive decoding at the codec level, since this is a feature that is very specific to still images. In a video format, it is of little use to be able to show a preview of a single frame — if you don’t have enough bandwidth to buffer many frames worth of video data, there’s little point in trying to play the video. Video formats have their own solutions to deal with varying network conditions (e.g. HLS).
To overcome this shortcoming of the currently available ‘new’ image formats (WebP and AVIF), web developers have resorted to other tricks to create a progressive loading experience, for example using low-quality image placeholders.
By contrast, JPEG XL not only supports progressive decoding, it also extends beyond what is possible in the old JPEG, for example, saliency-based progression. This is quite exciting and can improve things for both the web developer (no more need for placeholder complications) and the end-user experience.
JPEG XL can do lossless image compression in a way that beats existing formats (in particular PNG) in all ways: it can be faster to encode, produces smaller files, and more features are available (e.g. CMYK, layers, and 32-bit floating point samples). As this is mostly relevant for authoring workflows, not so much for the web delivery use case, I will not dwell on this topic too much more, but it sure is a rather important ‘benefit’ of JPEG XL as a format in general.
Even for the specific use case of web delivery, lossless compression can in some cases be desirable because for some types of image content (e.g. screenshots or pixel art), lossless compression can paradoxically produce smaller files than lossy compression. PNG and lossless WebP do have their uses on the web — not for photographic images, but for some kinds of non-photographic images.
This is, of course, a critical aspect of any image format used for web delivery: how well does it compress?
This is not an easy question to answer. Unlike lossless compression (where you can simply look at the file sizes), lossy compression is always a trade-off between compression and quality. With recent, more complicated and expressive codecs, one should also add encode speed to that trade-off — by spending more encoding time, better results can be obtained, but what kind of encode time is acceptable depends on the use case: for a single hero image on a landing page that will get millions of hits, it could be acceptable to spend a few minutes on encoding it, while for an image on social media, the latency and CPU cost requirements will be much more stringent.
Measuring compression (bits per pixel) and encode speed (megapixels per second) is simple enough: these are just numbers. Measuring image quality, however, is much harder.
There are two approaches to image quality assessment: subjective experiments and objective metrics. Subjective experiments, if performed correctly, are still the only reliable way to assess image quality, but it requires human participants to rate or compare images, so it is not a convenient nor cheap way to assess the performance of image encoders. For that reason, objective metrics are often used in practice: these are algorithms that take an original, uncompressed image and an image with lossy compression as input and compute a score that supposedly indicates the image quality.
Objective metrics should always be taken with a grain of salt, because their correlation with human opinions is not perfect and can even be quite low for some of the older metrics — the usefulness of a metric tends to drop over time, since if it is a widely used metric, encoders will tend to get better at ‘fooling the metric’ without actually improving the image quality. As an illustration of how metrics can get things wrong, I made a “Hall of shame” image gallery showing three images per row (compressed A, original, compressed B), where many metrics (all metrics except one I recently developed) are saying that image B on the right has a higher quality than image A on the left, even though human raters will likely say the opposite.
At Cloudinary, we recently performed a large-scale subjective image quality assessment experiment, involving over 40,000 test subjects and 1.4 million scores. We are currently still preparing a publication of our detailed results, but as an overall summary: in the quality range relevant for the web, JPEG XL can obtain 10 to 15% better compression than AVIF, at encoder speed settings where JPEG XL encoding is about three times as fast as AVIF. The compression gains are of course higher when comparing to WebP (about 20 to 25%) and MozJPEG (about 30 to 35% — note that MozJPEG itself has 10 to 15% better compression in the web quality range than typical JPEG encoders like libjpeg-turbo or the encoders used by cameras).
In the following chart with aggregated results for 250 different images, the 10th worst percentile rating is shown per encode setting — it makes more sense to evaluate based on worst-case performance than based on the average case.

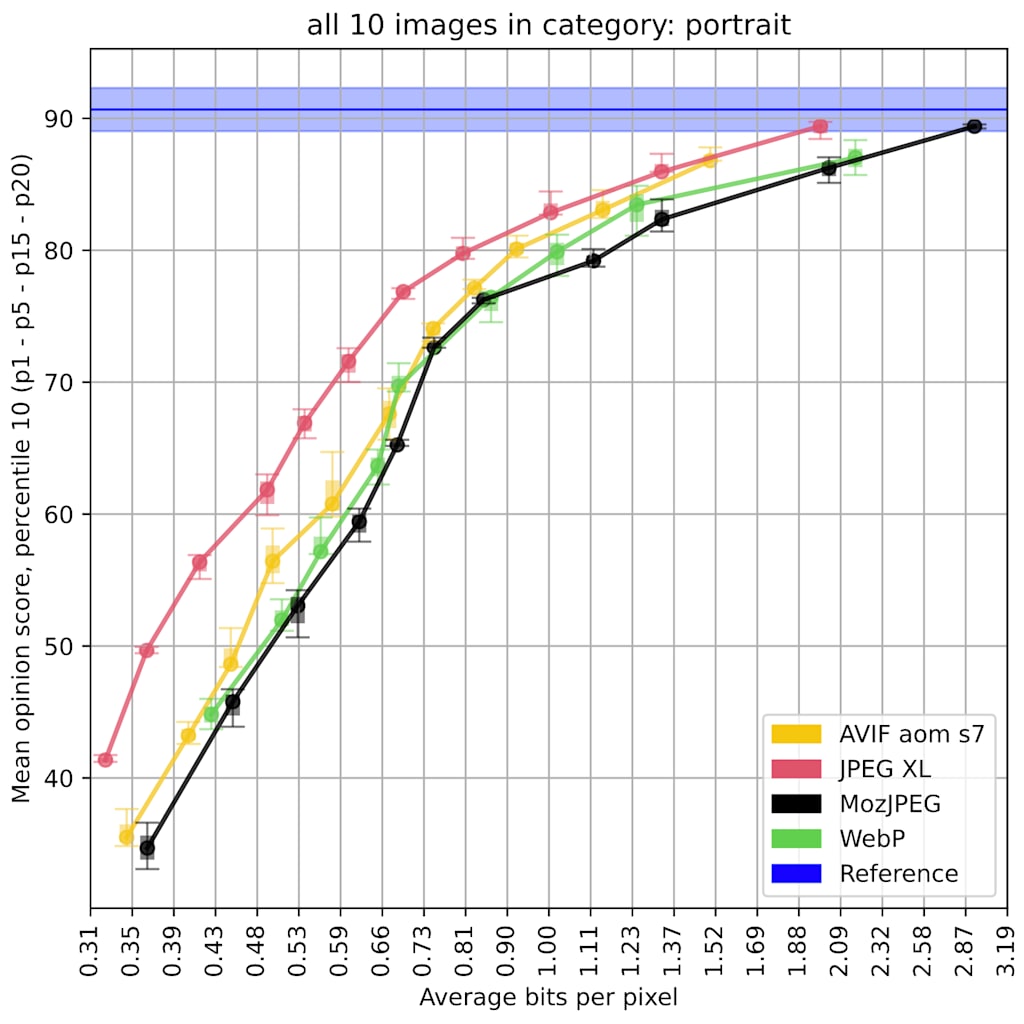
Looking at specific types of image content, like portrait photos, the gap between JPEG XL and existing formats can be even larger:
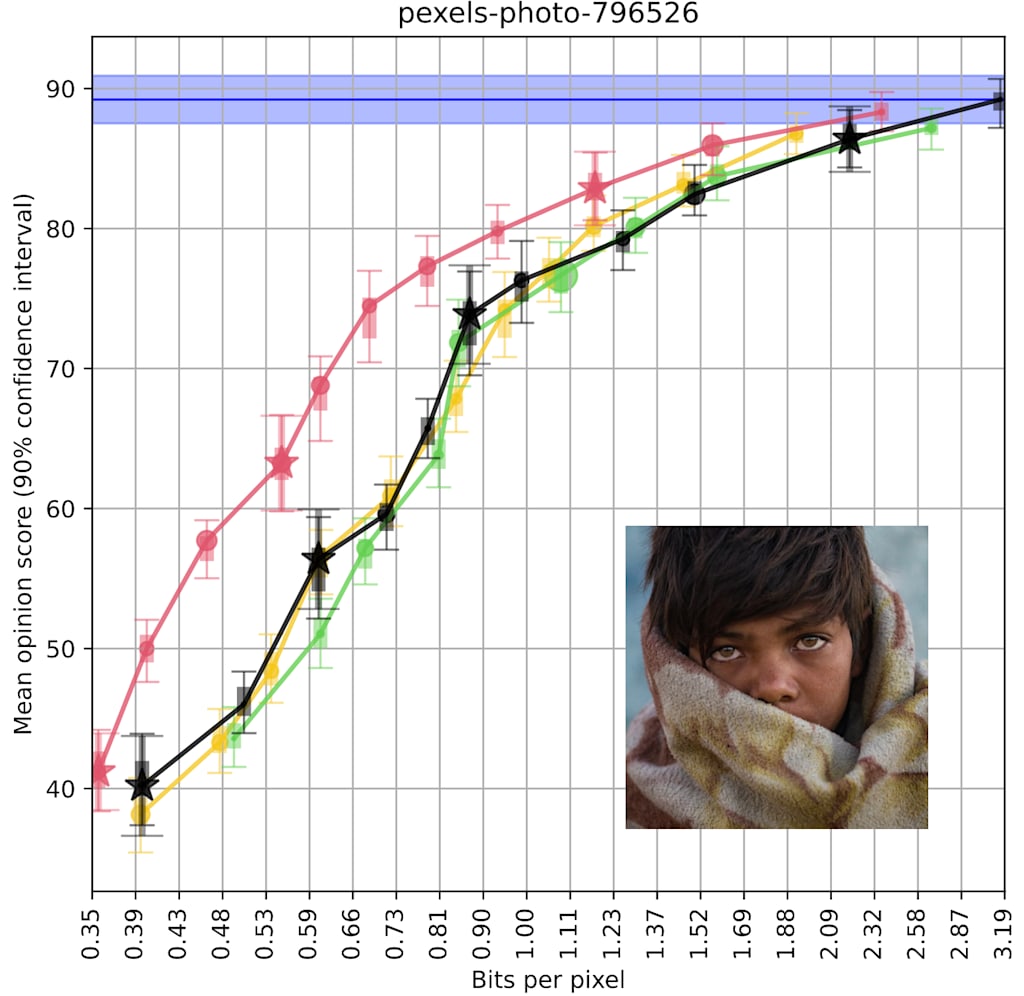
At the level of individual images, there are cases where the gap between JPEG XL and the next-best format is as wide as 30% or even more:
When assessing the quality using objective metrics, the outcome will depend heavily on the metric that is used, the encoder settings, and how the data is aggregated over multiple images. The currently best available perceptual metrics — according to their statistical correlation with subjective results — are Butteraugli, DSSIM, and SSIMULACRA 2. They do mostly agree with one another and with our subjective results: JPEG XL outperforms the existing formats quite clearly, by a 10 to 15% margin. AVIF encoders need about 100 times as much time to obtain comparable compression to JPEG XL; at a more practical encode speed (say 2-3 times slower than JPEG XL at default effort), AVIF obtains 10 to 15% worse compression than JPEG XL; at the same encode speed, AVIF is not better or even somewhat worse than MozJPEG while JPEG XL is 20 to 40% better.
Now is this a “sufficient incremental benefit”? This can be a matter of opinion: how many percent of compression improvement is enough to justify adding another format to a browser? At what point do the savings in bandwidth (and storage, and CPU cost) justify the additional binary size, the additional security and bug surface and maintenance burden introduced by the extra code? That is not a trivial decision.
In any case, just looking at the compression improvement itself: with the currently available encoders — in the case of JPEG XL and AVIF, encoders are still getting better so the situation can change — and at reasonable and more or less comparable encode speeds, the overall improvement going from (Moz)JPEG to WebP is about as large as the improvement going from WebP to AVIF, while the improvement going from AVIF to JPEG XL is larger than that and roughly comparable to the improvement going from JPEG to AVIF.
The reference implementation of JPEG XL, libjxl, includes an encoder that can be used as-is in production environments: it is relatively fast and produces a consistent visual quality for a given fidelity target. Encode speed isrelatively straightforward to understand and measure, but consistency is something that requires some explanation.
Image (and video) encoders can typically be configured with a “quality” setting, say on a scale from 0 to 100, which controls the fidelity of the encoding. However, the same quality setting, applied to different images, does not necessarily result in the same visual quality. While the codec algorithm might be performing similar actions, the effect of this on the actual perceived image quality is dependent on the specific image content. This phenomenon — imperfect encoder consistency — is the reason why we introduced an automatic quality selection method in Cloudinary (“q_auto”) back in 2016.
One way to characterize the consistency of an encoder is to compare the average visual result of a given quality setting to the worst-case results — say the score at percentile 1 or 10. In our subjective experiment, we obtained opinion scores on many different images (225 photographic ones and 25 non-photographic ones), so we can take a look at the spread between the worst-case score and the average score:
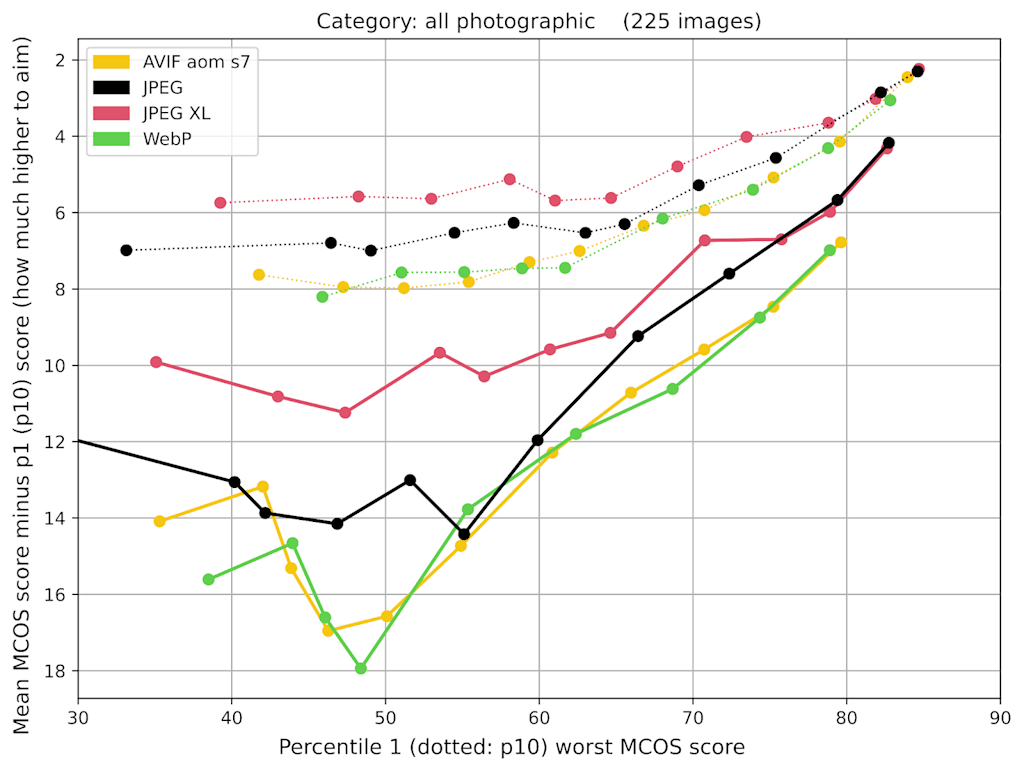
For example, to reach a mean opinion score of 60 (“medium-high quality”) in 99% of the cases, using JPEG XL you would need to use a setting that aims at a score of just under 70 (“high quality”) while using the existing formats (JPEG, WebP, AVIF) you would need to aim at a score of 72 or more.
In practical deployments, this means the actual compression gains that are obtainable with JPEG XL are higher than what would be suggested by considering average performance. The reason for this is that encoder settings are typically chosen such that 99% (or even 99.9%) of the images will have an acceptable visual quality, not just 50%. Better encoder consistency implies more predictable, reliable results — so there is less reason to “aim too high” to account for image-dependent variation.
One final significant benefit of JPEG XL is that it has a broad scope: while it is a great format for web delivery, this is not the only use case it was designed for. JPEG XL can also be used as a capture format, where it can play a role similar to current camera raw formats: high precision, high dynamic range, lossless or minimal lossy compression. It can also be used as an authoring format, supporting named layers, selection masks, multiple alpha channels. It can be used for printing use cases, supporting e.g. CMYK and spot colors. It can be used for medical or scientific applications, supporting high-precision lossless compression and multispectral imaging. And so on. It is a general-purpose format that covers many different use cases for digital imaging.
Of course, web image delivery was always the most important use case we had in mind while designing JPEG XL. But it was not the only use case. We did not assume that it would be used only on the web — unlike for example WebP, which as the name already indicates, was designed specifically for the web and only for the web. WebP was designed as a special-purpose image format specifically for the web, so it does have various limitations, e.g. regarding quality (forcing TV-range 4:2:0 chroma subsampling, which does not allow high fidelity lossy compression), image size (maximum 16383 pixels in either dimension, which is OK for the web but not for many other use cases), bit depth (8-bit only) and color space (RGB only). These limitations are all reasonable for the web use case, but not for a general-purpose image format.
JPEG XL is the first serious candidate to become a universal image format that “works across the workflow”, in the sense that it is suitable for the lifecycle of a digital image, from capture and authoring to interchange, archival, and delivery. For web developers, this has the advantage that there are fewer interoperability issues and conversion processes needed in digital asset management; for end-users, it means they can save images from webpages and expect them to ‘just work’ in other applications outside the browser. Obviously, JPEG XL is not there yet in terms of adoption, but at least it is plausible that it can obtain broader adoption than formats that limit their scope to web delivery only and don’t bring significant benefits to other use cases.
In the past, new image formats have been introduced that brought improvements in some areas while also introducing regressions in others. For example, PNG was a great improvement over GIF, except that it did not support animation. WebP brought compression improvements over JPEG in the low to medium fidelity range but at the cost of losing progressive decoding and high-fidelity 4:4:4 encoding. AVIF improved compression further, but at the cost of both progressive decoding and deployable encoders.
We looked at six aspects of JPEG XL where it brings significant benefits over existing image formats:
- Lossless JPEG recompression
- Progressive decoding
- Lossless compression performance
- Lossy compression performance
- Deployable encoder
- Works across the workflow
The reader can judge for themselves if they consider these benefits sufficient. In my opinion, every one of these benefits is sufficient. Most importantly, JPEG XL can bring these benefits without introducing a regression in other areas, at least in terms of technical strengths. Obviously, in terms of interoperability and adoption, every new format has a long way to go to catch up with existing formats like JPEG and PNG. We can only hope that the Chrome developers reverse their decision and help JPEG XL catch up with the old formats in terms of software support, so we can all enjoy the benefits it brings.